

In my last post, I have explained how to deploy SQL Server on GKE. In this post, we will deploy SQL Server in a highly available mode on GKE using SQL Server’s native HADR method — AlwaysOn Availability Groups. SQL Server’s latest and greatest — SQL Server 2019 supports AlwaysOn Availability groups on Kubernetes. So let’s get started.
What will we build ?
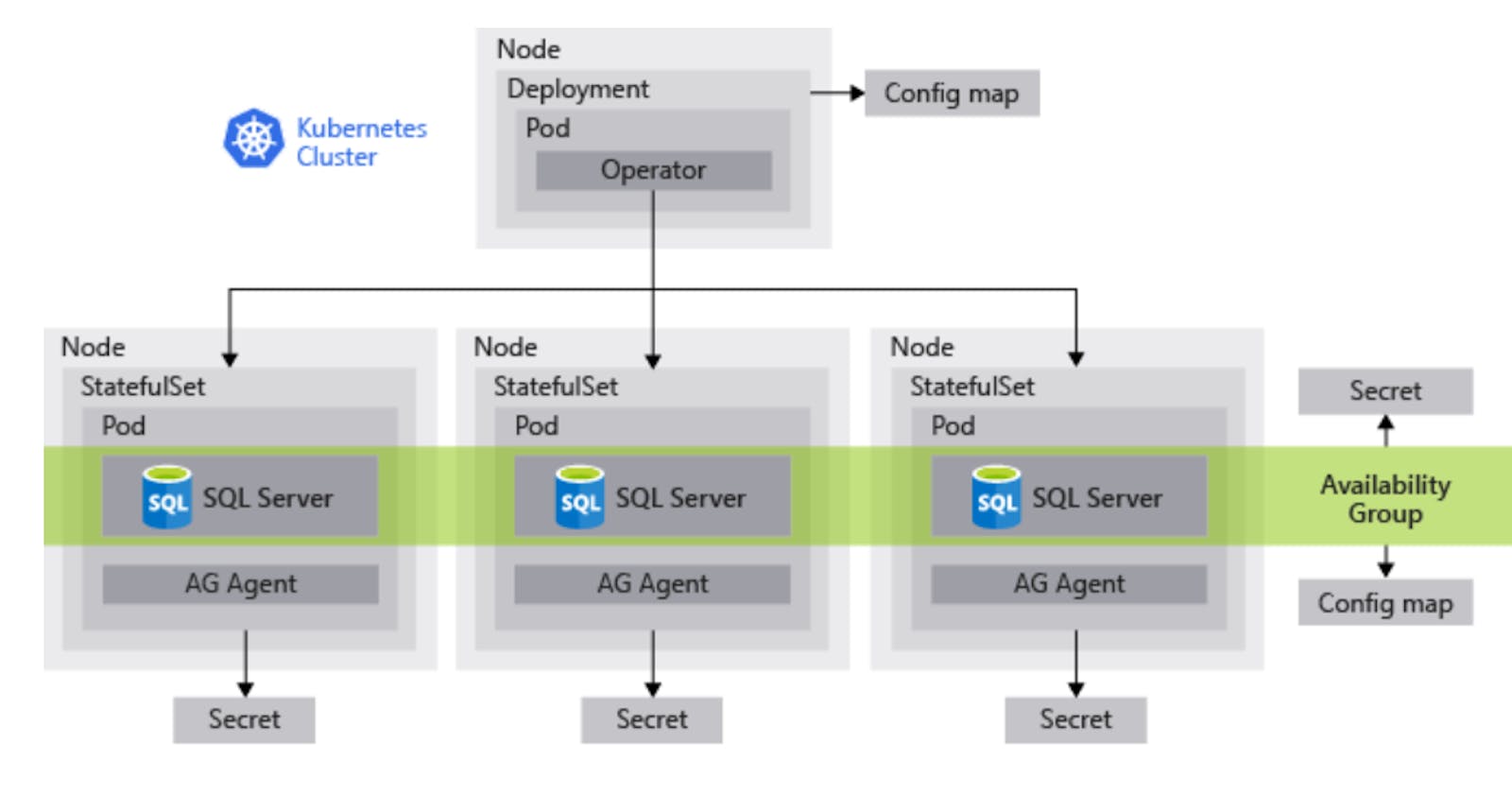
](https://cdn-images-1.medium.com/max/2284/1*RUU11-PAM7VinqHHFyz7Ow.png) Image Source: Microsoft Documentation
Image Source: Microsoft Documentation
A GKE cluster with 4 worker nodes.
SQL Server HA Operator pod, which is a key component that provides ability to deploy, manage and maintain the SQL Server HA deployment
3 SQL Server stateful sets (one primary and two read replicas) along with an AG Agent
Secrets to manage sa credentials, sql server master key
Persistent volume claims for SQL Server pods
ConfigMaps for operator and availability group
Deploy
The official Microsoft SQL Server sample manifests are helpful to come up with the GKE versions, you can find them here. The manifests used in this post are available at the following repo: yogirk/mssql-ha-gke Deploying Microsoft SQL Server Always on Availability Groups on GKE - yogirk/mssql-ha-gkegithub.com
Create a GKE cluster, we will choose an additional zone to make sure that the nodes are spread across. Make sure you choose the latest cluster version( 1.11.6-gke.2) , I ran into issues related to sql server pods crashing with default GKE cluster version.
gcloud beta container --project "searce-sandbox" clusters \
create "mssql-ag-gke-rk" --zone "us-west1-a" --username "admin" \
--cluster-version "1.11.6-gke.2" --machine-type "custom-2-4096" \
--image-type "COS" --disk-type "pd-standard" --disk-size "100" \
--num-nodes "2" --additional-zones "us-west1-b"
Get credentials to interact with the cluster
gcloud container clusters get-credentials mssql-ag-gke-rk --zone=us-west1-a
We will now create SQL Server HA operator manifest and deploy, but before that you must grant yourself the ability to create roles in kubernetes because the operator deployment involves using role based access control
kubectl create clusterrolebinding cluster-admin-binding \ --clusterrole cluster-admin --user your.email@domain.com
Create a kubernetes namespace
kubectl create namespace mssql-ag
Also create secrets
kubectl create secret generic sql-secrets --from-literal=sapassword="xxxxx" --from-literal=masterkeypassword="xxxxx" --namespace mssql-ag
Apply the SQL Server HA Operator manifest, operator.yaml. This creates an operator pod
kubectl apply -f [https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/operator.yaml](https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/operator.yaml) --namespace mssql-ag

Create persistent volume claims for SQL Server pods.
kubectl apply -f [https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/sqlvolumes.yaml](https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/sqlvolumes.yaml) --namespace mssql-ag

We can now deploy SQL Server using sqlserver.yaml. This creates mssql1, mssql2, mssql3 services.
kubectl apply -f [https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/sqlserver.yaml](https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/sqlserver.yaml) --namespace mssql-ag

We will now apply the manifest for loadbalancing services to allow access to SQL Server primary and to any of the read replicas.
kubectl apply -f [https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/mssql-ag-services.yaml](https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/mssql-ag-services.yaml) --namespace mssql-ag
There you go! If everything went according to the plan, we should now have a fully functional AlwaysOn Availability Group deployed on GKE. Let’s explore.
kubectl get services --namespace mssql-ag
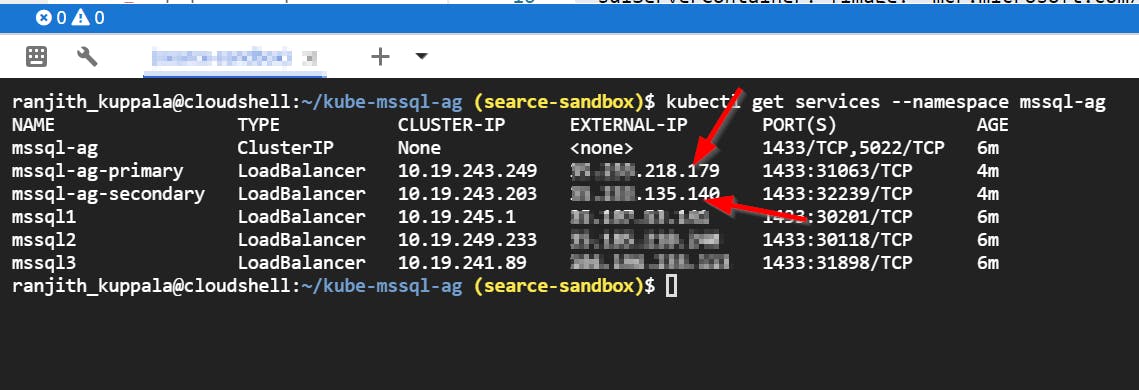 Endpoints for primary instanceand secondary replicas
Endpoints for primary instanceand secondary replicas
Add Database to AG
Let’s now connect, create a user database and add it to the availability group. You can use SSMS or mssql-cli (btw, try this. Finally a cool cli tool for SQL Server)

Let’s create a database and add it to the availability group.
USE master
CREATE DATABASE DBAdmin;
In order to add to the AG, you need a full backup — which initiates LSN chain.
USE master
BACKUP DATABASE DBAdmin TO DISK =N'/var/opt/mssql/data/demodb.bak'
Add to the availability group
ALTER AVAILABILITY GROUP [mssql-ag] ADD DATABASE [DBAdmin]

Let’s fire up SSMS and look at the setup in its full glory now :)

Failover
For some reason, mssql2 pod became a primary in my setup and I would like to change that — let’s do a failover. Apply the failover.yaml manifest (by editing the desired pod name to failover to)
kubectl apply -f [https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/failover.yaml](https://raw.githubusercontent.com/yogirk/mssql-ha-gke/master/failover.yaml) --namespace mssql-ag
You can verify whether this job succeeded here:

Sure enough, the new primary is mssql1-0

If you try failover using TSQL commands, it won’t work because it’s an external failover type.

That’s it. Hope you found this useful! Happy containerizing :)