


Image Credit: Bhuvi
If the post’s title brought you here — you either know SQL Server or Kubernetes(or both), so we will skip the intros.
It was possible to run Microsoft SQL Server on Docker and it was generally used by enthusiastic DBAs to geek out or dev/experimental environments. With SQL Server’s availability in Linux and the way the platform has been evolving, I think there will soon come a time when running SQL Server workloads on Kubernetes for production will no longer be frowned upon. Also, imagine running .NET core apps with SQL Server backend. Both on GKE. How cool would that be? :)
So, how do we deploy SQL Server on GKE?
Let’s start creating a GKE cluster. For the sake of brevity, we will use gcloudcommand line tools. We are going to spin a two worker node GKE cluster.
gcloud beta container --project "searce-sandbox" clusters create "mssql-gke-rk" --zone "asia-south1-a" --username "admin" --cluster-version "1.10.9-gke.5" --machine-type "custom-1-2048" --image-type "COS" --disk-type "pd-standard" --disk-size "100" --num-nodes=2
let’s switch to working on this cluster — this command will generate a kubeconfig entry so that we can interact with the cluster in next steps using kubectl
gcloud container clusters get-credentials mssql-gke-rk \
--zone=asia-south1-a
SQL Server installations require a system admin account, sa . Let’s create a Kubernetes secret which will later use in deployment.
kubectl create secret generic mssql-secrets --from-literal=SA_PASSWORD="YourSuperComplexPassword!!"
Since this is a database server, we need our storage to be durable and persist across pods coming up and going down etc. When you are doing generic VM based installations of SQL Server — its one of the best practices that the SQL Server database data files (mdf) and log files(ldf) and TempDB are configured in different storage volumes because SQL Server’s access methods of data and log files are different — random read/writes vs sequential. We could tap into environment variables and define different volumes for user data and log files for a production like deployment. Unfortunately, the tempdb location is not configurable via environment variable, so we have to live with it for now. We will use GKE’s Persistent Volume Claims and create three volumes.
#mssql base volume claim: mssql-base-volume.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-base-volume
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
#mssql data volume claim: mssql-mdf-volume.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-mdf-volume
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
#mssql logs volume claim: mssql-ldf-volume.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-ldf-volume
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
Create volume claims
kubectl apply -f mssql-base-volume.yaml
kubectl apply -f mssql-mdf-volume.yaml
kubectl apply -f mssql-ldf-volume.yaml
Verify volume claims

Let’s deploy SQL Server now using the following deployment file.
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: mssql-gke-rk
spec:
replicas: 1
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mssql
image: mcr.microsoft.com/mssql/server:2017-latest
ports:
- containerPort: 1433
env:
- name: ACCEPT_EULA
value: "Y"
- name: SA_PASSWORD
valueFrom:
secretKeyRef:
name: mssql-secrets
key: SA_PASSWORD
- name: MSSQL_DATA_DIR
value: /var/opt/mssql/mdf
- name: MSSQL_LOG_DIR
value: /var/opt/mssql/ldf
volumeMounts:
- name: mssql-base-volume
mountPath: /var/opt/mssql
- name: mssql-ldf-volume
mountPath: /var/opt/mssql/ldf
- name: mssql-mdf-volume
mountPath: /var/opt/mssql/mdf
volumes:
- name: mssql-base-volume
persistentVolumeClaim:
claimName: mssql-base-volume
- name: mssql-mdf-volume
persistentVolumeClaim:
claimName: mssql-mdf-volume
- name: mssql-ldf-volume
persistentVolumeClaim:
claimName: mssql-ldf-volume
---
apiVersion: v1
kind: Service
metadata:
name: mssql-deployment
spec:
selector:
app: mssql
ports:
- protocol: TCP
port: 1433
targetPort: 1433
type: LoadBalancer
Deploy
kubectl apply -f mssql-deploy.yaml
Check services
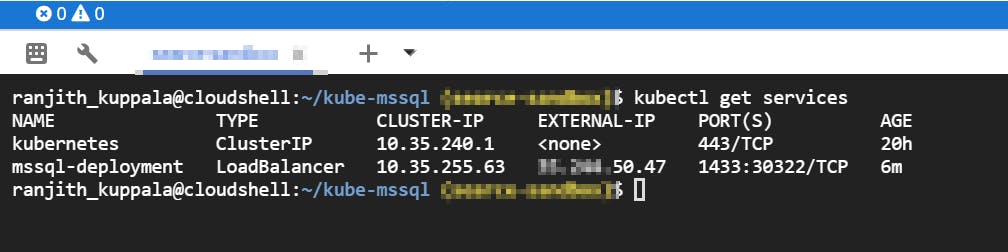
There you go! SQL Server is now deployed on GKE and can be accessed using your favorite client. Mine happens to be SSMS.

Just for kicks and giggles — I deleted the pod and saw a new pod coming up, SQL Server accepting connections in under 20 sec.
In the next post, we will deploy SQL Server in HA mode using Availability Groups on Kubernetes.
Hope you find this useful. Happy containerizing!