

One of our customers was running a 17 node cassandra cluster (DSE) on AWC EC2 and we had to come up with a backup strategy for it. The customer was running a fairly large environment with multiple application servers running across availability zones and we also had to automate EBS snapshots for them.
DSE was deployed using the default placement strategy(NetworkTopologyStrategy) with a replication factor of 2. While we automated EBS snapshots for all the instances using awesome script available at AWS missing tools and it is a multi datacenter deployment with replication enabled, we can neither rely on volume snapshots for transactionally consistent backups nor can replication take care of availability. Imagine someone accidentally dropping a keyspace - this will propagate to the other nodes. How do you recover from such errors?
Nodetool backups
Nodetool allows you to perform Cassandra backups at node level. When you run nodetool snapshot, cassandra backs up data by snapshotting all on disk data files (SST Table files) that are present in data directory. You can take a snapshot on all keyspaces, a single keyspace, or a single column family while the system is online. But restoring from these snapshots will require the node to be down.
Nodetool Considerations
When you run a snapshot using nodetool, it first flushes all in-memory writes to the disk and makes hard link of SST table files for each keyspace. You need to maintain enough disk space to allow snapshots. Since snapshots prevent obsolete files from being deleted, they can quickly cause disk space issues as they stack up and there should a process in place for moving snapshots etc.
Taking nodetool snapshots
By design nodetool snapshot is one node at a time. In order to produce an eventually consistent backup across all nodes,
you may use a tool like Ansible or simple pssh to run the snapshot across all nodes parallelly.
The command itself is pretty simple, just run:
nodetool -h localhost -p 7199 snapshot mydb
Removing a snapshot is simple too:
nodetool -h localhost -p 7199 clearsnapshot
The problem with node tool is that you do not have a straight forward and easily manageable way to schedule backups, perform point time restorations etc. Also, if you need to move these backups to an object store like S3, you need to come up with your own jobs. These are some of the problems that OpsCenter solves pretty well.
OpsCenter Backups
OpsCenter is a web based cluster management and monitoring tool for DSE. Fortunately, this customer had OpsCenter because they were running enterprise version and we decided to go ahead with OpsCenter backups and restores. Some of the features:
You can schedule backups at keyspace and/or table level and also backup commit logs too.
Get notified when a job fails
OpsCentertakes backups to the local storage by default but you can also specify another location ass3 bucketBackup compression and backup retention can be configured
You can perform a full, table level restorations quite easily. If commit logs are enabled, you can perform point-in-time restorations too.
A full cluster clone is possible using
OpsCenter- clone a production cluster to a dev/test.
We eneded up implementing this for the customer and we tested the fucntionality thoroughly during a DR drill on stage environment. Below are the details that might help someone while using OpsCenter
How to Schedule Backups
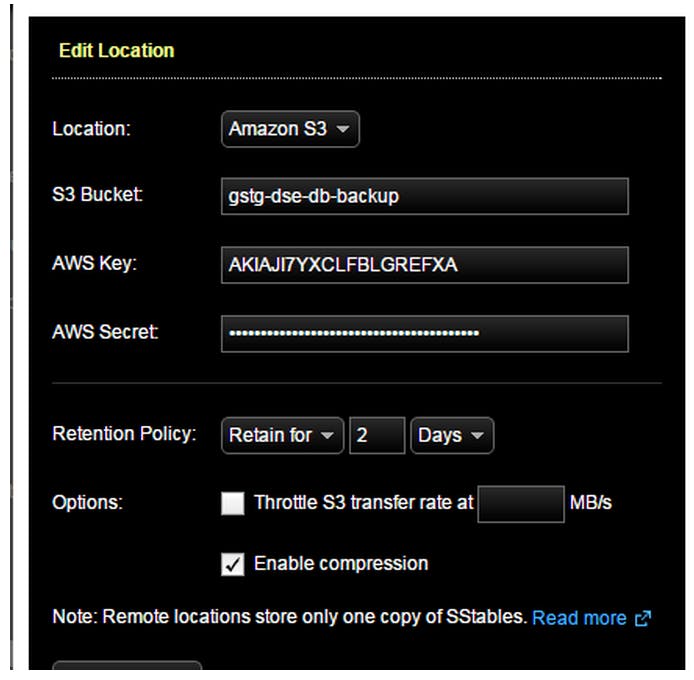
From the amazon console, create an S3 bucket which will be used to store DSE data backups. Grant access to a User which has access only to this S3 bucket using IAM policies. Get the Bucket name, Secret Key and Access Key.
Note: In AWS, data out between regions is charged and it has to be considered before creating a bucket. It is preferred to create a bucket in the same region as that of DSE cluster.
Visit the OpsCenter URL and navigate to Services.

Click on Configure on Backup Services

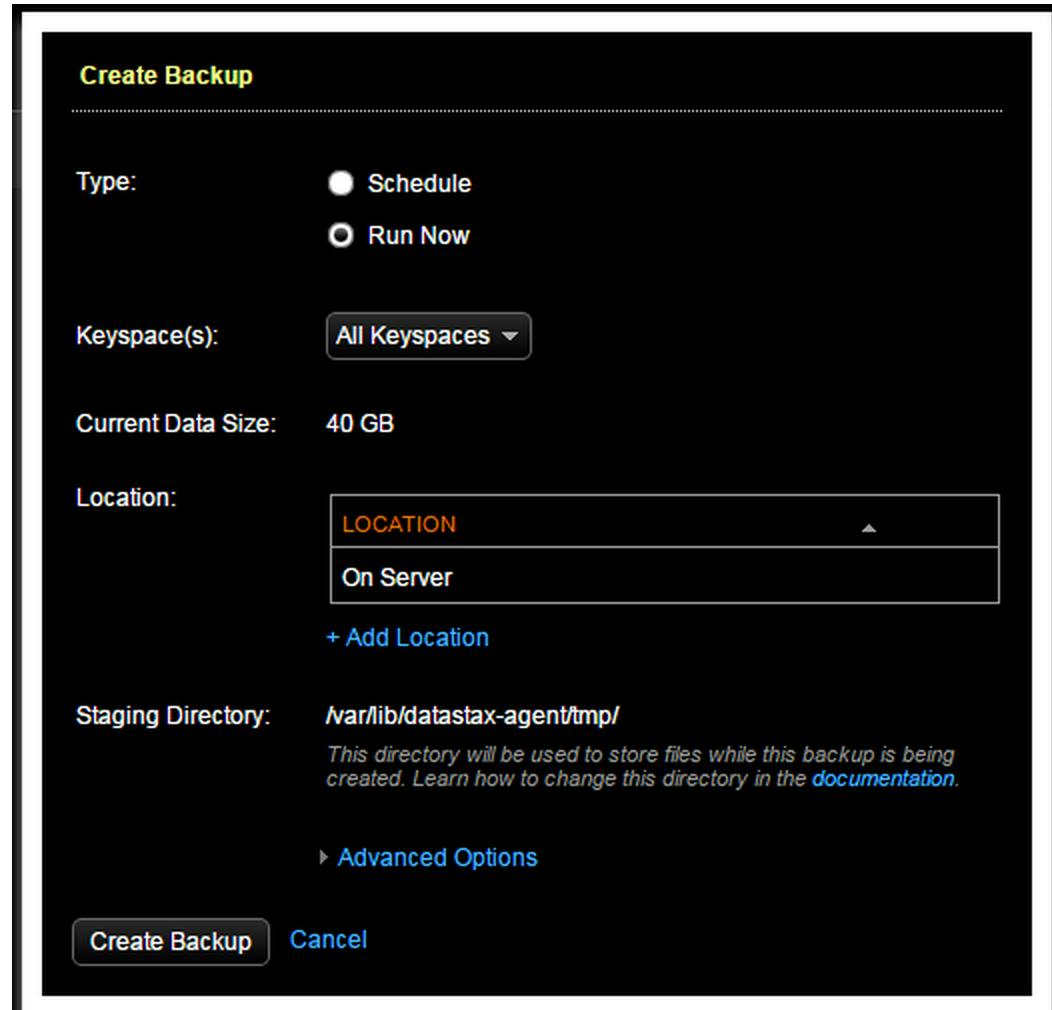
We can either create an ad-hoc backup operation or schedule a proper backup

Select keyspaces (generally all — for full protection)
Choose the bucket you created earlier and provide access key and secret key. Configure retention policy as required.(don’t get cute with the access key and try to hack. This was generated for test and removed :))
Create Backup

If all went well, it should look like this

Restoring from Backup
Click the name of the cluster you want to manage from the left pane.
Click Services.
Click View Details for the Backup Service.
Click Restore Backup.
Select the backup that contains the data you want to clone and click Next.
If the
OpsCenterinstance does not manage the cluster you want to clone, you can clone it if the cluster data was backed up to an S3 location from another OpsCenter instance. Then select the Other Location tab in Restore from Backup to enter the S3 information to retrieve the backed up data.Click Other Location.
Enter the S3 bucket name under S3 Bucket.
Enter your AWS credentials under AWS Key and AWS Secret.
Select the tables included in the backup you want to restore. Click the keyspace name to include all the tables in the keyspace.
Click All Keyspaces to restore all the keyspaces.
To select only specific tables, expand the keyspace name and select the tables.
Here we go:
