

As part of building an enterprise DW for one of our customers we had to sync a bunch of tables from a MYSQL slave to BigQuery at 30 min intervals. Considering the range of other non-relational data sources which will be part of the this load, we chose Matillion as ETL tool. Matillion is easy to setup (just provision the VM and start authoring jobs) and long list of integrations so it made sense.
This post explains building a Matillion job that does the following:
Full Load
Incremental load for tables with larger row count and an
IDthat can be looked up for new rows since last load.
MYSQL Drivers
If you came from a Google search looking for Matillion — I am assuming you are done with provisioning the instance, setting up default project etc are done, so I am skipping those. While Matillion ships with PostgreSQL drivers, for some reason it doesn’t have MYSQL drivers — you have to initially set them up.
Download the driver from here. Unzip to the jar file
In Matillion, go to Project -> Manage Database Drivers, upload the jar file and test. You are now good to go.
Full Loads
We have a bunch of tables with a few thousand records. Each of these table would take less than two seconds even if we do a full table load every time — so we went ahead with that approach. Doing this on Matillion is straightforward.
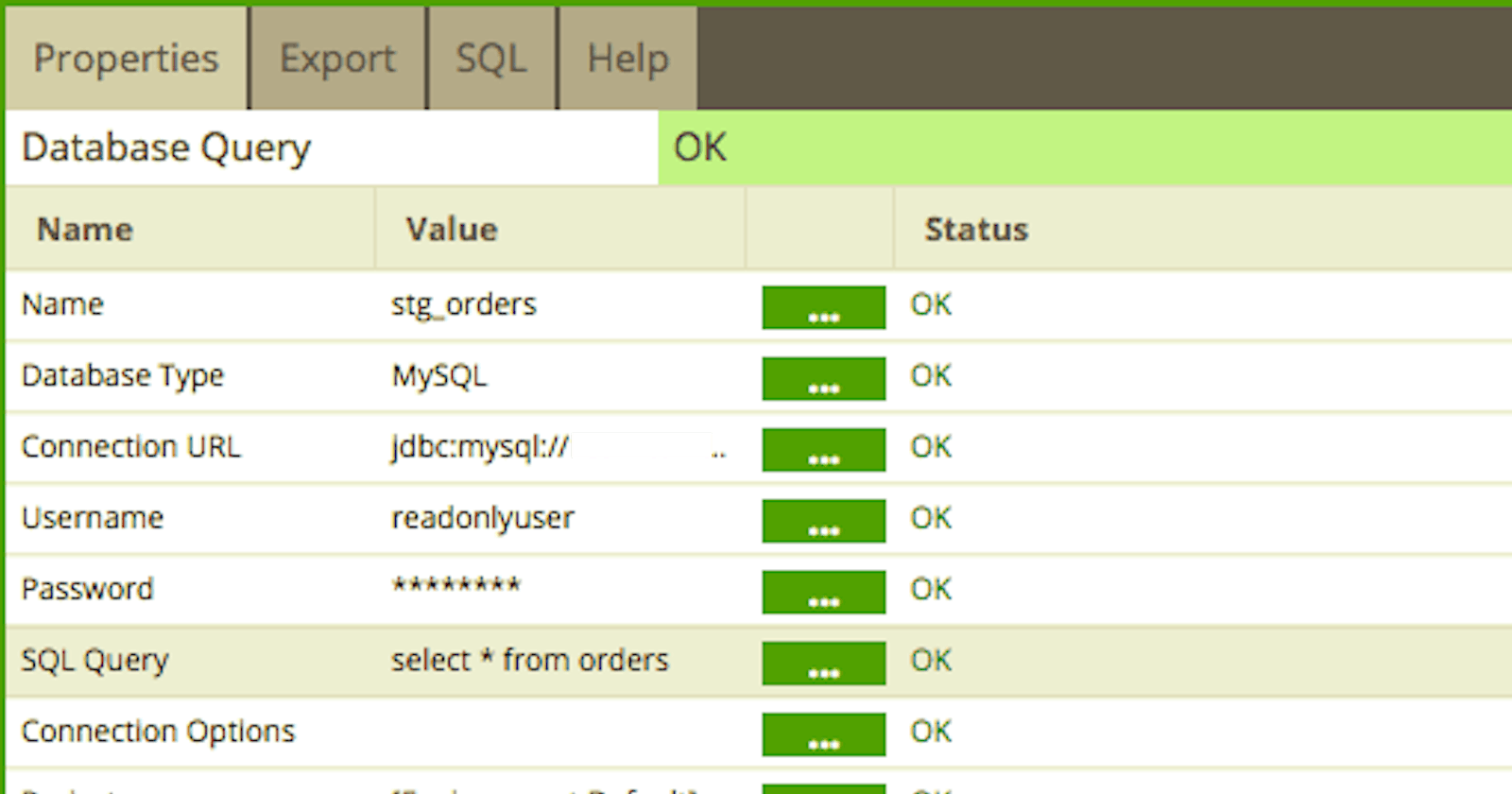
Choose the Database Query component and configure it with source and target.


Matillion takes care of creating the target tables on BQ, even if they don’t exist — which is cool. But remember that this component always recreates the target table and you shouldn’t be doing this for incremental.
Incremental Loads
We also have a few tables whose row count is more than 50 mln and they keep growing. Doing a full load in this case takes a lot of time. Fortunately we have an id column, primary key on all of these tables which allows performing a lookup for the MAX(ID) and only import new rows that go added since the last load. Matillion’s documentation had steps for achieving this for Amazon RDS for multiple tables, but not quite the same use case as ours.
So the steps involved are below:
Perform a full load of the target table to begin with. You can use the
Database Querycomponent to do this. Lets say the source table name on mysql isorders, you will perform a full load tostg_ordersin BigQuery in this step. This is onetime and you can remove the component after load.Use the Python script component to lookup the MAX(ID) from
stg_orderstable on BigQuery, store it in a variable. You need the following code snippet inside Python component. This stores the current maxid value inmaxidvariable which is available for the next step.
cursor = context.cursor()
cursor.execute(‘select max(id) from stg_orders’)
result = cursor.fetchone()
context.updateVariable(“maxid”, str(result[0]))
- Create a temporary table on BQ to stage the new rows during each load. You can again use the
Database Querycomponent. Lets call our temp table asstg_orders_tmp. In the component configuration, just edit the SQL Query to return rows greater than maxid.

- Next, author a transformation job to read the data from the temp table we created above and update. The components we will use will be,
Table InputandTable Update. The table input reads data from previous step, and updated the target table on BQ withUpdate/InsertUpdate strategy of the component.

- Now, come back to the orchestration job and add transformation job as next step. So the job would look like this. The right side of the flow is full loads, while the left side is incremental load.

Hope you found this useful. Happy loading! :)